Elastic Stack
1. 简介
1.1 elasticStack简介
包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
ELK是一个免费开源的日志分析架构技术栈总称,官网https://www.elastic.co/cn。包含三大基础组件,分别是Elasticsearch、Logstash、Kibana。但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据搜索、分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。下面是ELK架构:
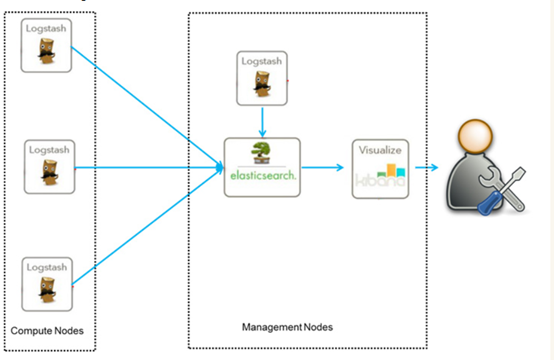
随着elk的发展,又有新成员Beats、elastic cloud的加入,所以就形成了Elastic Stack。所以说,ELK是旧的称呼,Elastic Stack是新的名字。

1.2 特点
- 处理方式灵活:elasticsearch是目前最流行的准实时全文检索引擎,具有高速检索大数据的能力。
- 配置简单:安装elk的每个组件,仅需配置每个组件的一个配置文件即可。修改处不多,因为大量参数已经默认配在系统中,修改想要修改的选项即可。
- 接口简单:采用json形式RESTFUL API接受数据并响应,无关语言。
- 性能高效:elasticsearch基于优秀的全文搜索技术Lucene,采用倒排索引,可以轻易地在百亿级别数据量下,搜索出想要的内容,并且是秒级响应。
- 灵活扩展:elasticsearch和logstash都可以根据集群规模线性拓展,elasticsearch内部自动实现集群协作。
- 数据展现华丽:kibana作为前端展现工具,图表华丽,配置简单。
1.3 组件介绍
Elasticsearch
Elasticsearch 是使用java开发,基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
Logstash 基于java开发,是一个数据抽取转化工具。一般工作方式为c/s架构,client端安装在需要收集信息的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch或其他组件上去。
Kibana
Kibana 基于nodejs,也是一个开源和免费的可视化工具。Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
Beats
Beats 平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
Beats由如下组成:
Packetbeat:轻量型网络数据采集器,用于深挖网线上传输的数据,了解应用程序动态。Packetbeat 是一款轻量型网络数据包分析器,能够将数据发送至 Logstash 或 Elasticsearch。其支 持ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache等协议。
Filebeat:轻量型日志采集器。当您要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,请告别 SSH 吧。Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
Metricbeat :轻量型指标采集器。Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据,从 CPU 到内存,从 Redis 到 Nginx,不一而足。可定期获取外部系统的监控指标信息,其可以监控、收集 Apache http、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服务。
Winlogbeat:轻量型 Windows 事件日志采集器。用于密切监控基于 Windows 的基础设施上发生的事件。Winlogbeat 能够以一种轻量型的方式,将 Windows 事件日志实时地流式传输至 Elasticsearch 和 Logstash。
Auditbeat:轻量型审计日志采集器。收集您 Linux 审计框架的数据,监控文件完整性。Auditbeat 实时采集这些事件,然后发送到 Elastic Stack 其他部分做进一步分析。
Heartbeat:面向运行状态监测的轻量型采集器。通过主动探测来监测服务的可用性。通过给定 URL 列表,Heartbeat 仅仅询问:网站运行正常吗?Heartbeat 会将此信息和响应时间发送至 Elastic 的其他部分,以进行进一步分析。
Functionbeat:面向云端数据的无服务器采集器。在作为一项功能部署在云服务提供商的功能即服务 (FaaS) 平台上后,Functionbeat 即能收集、传送并监测来自您的云服务的相关数据。
Elastic cloud
基于 Elasticsearch 的软件即服务(SaaS)解决方案。通过 Elastic 的官方合作伙伴使用托管的 Elasticsearch 服务。

2. elasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于Restful web接口。ElasticSearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,ElasticSearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。它是 Elastic Stack的核心模块
2.1 elasticSearch简介
2.2 elasticSearch特点
2.2.1 NRT(Near Realtime):近实时
- 写入数据时,过1秒才会被搜索到,因为内部在分词、录入索引。
- es搜索时:搜索和分析数据需要秒级出结果。
2.2.2 Cluster:集群
包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。同一网络下,集群名一样的多个es实例自动组成集群,自动均衡分片等行为。默认集群名为“elasticsearch”。
2.2.3 Node:节点
每个es实例称为一个节点。节点名自动分配,也可以手动配置。
2.2.4 Index:索引
包含一堆有相似结构的文档数据。
索引创建规则:
- 仅限小写字母
不能包含\、/、 *、?、”、<、>、 、#以及空格符等特殊符号 - 从7.0版本开始不再包含冒号
- 不能以-、_或+开头
- 不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
2.2.5 Document:文档
es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。多个document存储于一个索引(Index)中。
#book document
{
"book_id": "1",
"book_name": "java编程思想",
"book_desc": "从Java的基础语法到最高级特性(深入的[面向对象](https://baike.baidu.com/item/面向对象)概念、多线程、自动项目构建、单元测试和调试等),本书都能逐步指导你轻松掌握。",
"category_id": "2",
"category_name": "java"
}
2.2.6 Field:字段
就像数据库中的列(Columns),定义每个document应该有的字段。
2.2.7 Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES官方将在ES9.0版本中彻底删除type。本教程typy都为_doc。
2.2.8 shard:分片
index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
2.2.9 replica:副本
在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。所以,为了保证数据的安全,我们会将每个index的分片经行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。
能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的我们就管他们叫做备份的分片(replica shard)。
es6默认新建索引时,5分片,2副本,也就是一主一备,共10个分片。所以,es集群最小规模为两台。
2.2.10 elasticsearch核心概念 vs. 数据库核心概念
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 索引Index(原为Type) |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
2.3 elasticSearch安装
本次安装环境为 CentOS release 7.2,使用elasticSearch的版本为 7.3.2。
2.3.1 下载
官网:https://www.elastic.co/cn/products/elastic-stack/features
下载页面: https://www.elastic.co/cn/downloads/
点击下图红框处可以选择更多版本。

2.3.2 安装
将下载的安装包 elasticsearch-7.3.2-linux-x86_64.tar.gz 上传至 linux服务器 /opt目录下。

执行解压命令,解压至 /usr/local/目录下。
tar -zxvf elasticsearch-7.3.2-linux-x86_64.tar.gz -C /usr/local/

2.3.3 启动
高版本的elasticSearch内置了java,因而启动前不用再安装java环境。
修改配置文件。
进入安装目录下的config配置目录 /usr/local/elasticsearch-7.3.2/config

vim 打开 elasticsearch.yml,修改配置 network.host: 0.0.0.0 ,保证任意IP均可以访问服务。线上服务不要这样设置,要设成具体的 IP。 cluster.initial_master_nodes: [“node-1”,”node-2”]中的node-2删除。
vim 打开 jvm.options,elasticserch默认分配1G内存,我们调小一点128m。

修改完后我们返回上级目录,执行 bin/elasticsearch 命令启动服务。

启动失败,提示不能使用root用户启动。那么我们创建elasticsearch用户,并修改安装目录权限。
#创建一个elasticsearch用户使用默认的elasticsearch用户组 useradd elasticsearch #修改文件所有权 cd .. chown elasticsearch:elasticsearch elasticsearch-7.3.2/ -R
#切换用户 su elasticsearch使用elasticsearch用户执行启动命令。

启动失败,这次是创建内存映射的最大数量太低。
#先切换回root用户 #修改进程在VMAs(虚拟内存区)创建的内存映射最大数量 vim /etc/sysctl.conf vm.max_map_count=655360 #配置生效 sysctl -p #除了上面的方式,还可以直接 sudo sysctl -w vm.max_map_count=262144再次使用elasticsearch用户启动,启动成功,但发现日志持续在连接集群信息 ,高版本elasticsearch应该默认有集群部署配置。前面已经修改了默认集群只有一个节点,不知道为什么没效果

修改集群配置,将节点名称均改为test,再次启动,启动成功。
这个是前台启动,启动没问题后我们加上-d参数后台启动 bin/elasticsearch -d
2.3.4 关闭
关闭后台启动的elasticSearch。
#使用jps命令查询进程号
jps
#再使用kill 进程号命令 关闭
kill 进程号

2.3.5 浏览器安装elasticSearch-head工具
这个工具有好几种安装方法,为了使用简单,我们选择chrome插件。具体请百度。
安装成功后,点击插件,输入服务地址ip点击链接,ok。

2.4 kibana安装
elasticSearch安装好后,我们可以通过restApi来进行操作,但是路径写起来挺麻烦,也没有代码提示,所以我们直接安装kibana,使用kibana来对elasticSearch进行操作。
2.4.1 下载
下载地址与elasticSearch基本一致。
2.4.2 安装
上传下载的安装包,并将安装包解压到/usr/local/目录下
tar -zxvf kibana-7.3.2-linux-x86_64.tar.gz /usr/local/ -C修改配置文件
进入安装目录的config文件夹下,修改kibanna.yml配置文件
#配置Kibana的远程访问 server.host: 0.0.0.0 #配置es访问地址,部署在一个服务器上所以用localshot elasticsearch.hosts: ["http://localhost:9200"] #汉化界面 i18n.locale: "zh-CN"执行 ./bin/kibana 命令来启动kibana。浏览器访问 地址:5601即可打开kibana。
后台启动 nohup ../bin/kibana &
2.5 RestApi
2.5.1 查看集群状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
#GET /_cat/health?v v表示显示字段名

如何快速了解集群的健康状况?green、yellow、red
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
2.5.2 查看集群中的索引
#GET /_cat/indices?v

2.5.3 创建非结构化索引
非结构化索引,即创建的索引结构并未被定义,会根据插入的数据来逐渐完善索引的定义,也就是逐步完善索引中各个字段的类型。
#PUT /[索引名]
PUT /kase
{
"settings": {
"number_of_shards": 2, #主分片2个
"number_of_replicas": 0 # 备份分片0
}
}
#响应
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "kase"
}
#删除索引
DELETE /kase
2.5.4 用户的CRUD
2.5.4.1 创建用户索引
创建用户索引,相当于创建用户表。user指索引名。
PUT /user
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}
2.5.4.2 新增用户
url规则:
POST /索引/类型/id
路径id不是必须的,如果不传的话会生成一个默认的id作为唯一标识符。
路径上的id和参数中的id没有必然的联系,路径id是对此条数据的标识与响应中的_id对应。
类型在高版本中已经废弃,默认均使用_doc。
#插入user
POST /user/_doc/1001
{
"id": 1001,
"name": "张三",
"age": 20,
"sex": "男"
}
#响应
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1001",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
在elasticSearch-head中就可以看到插入的数据。

路径不带id的插入,可以看到下面的响应中_id的值是自动生成的
#请求
POST /user/_doc
{
"id": 1002,
"name": "李四",
"age": 30,
"sex": "女"
}
#响应
{
"_index" : "user",
"_type" : "_doc",
"_id" : "C_uY2nEBlxTAU77RF9IH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
2.5.4.3 删除用户
url规则:DELETE /索引/类型/id
DELETE /user/_doc/1001
执行后将_id = 1001的数据删除掉。
如果删除一条不存在的数据,则会响应404,响应的结果会是 not_found
删除一个文档,不会立即从索引中删除,而是先标记为已删除,在后续操作中在统一删除。
2.5.4.4 更新用户
在elasticSearch中数据是不能被更改的,但是可以通过覆盖的方式来对数据进行更新
2.5.4.4.1 全量更新
PUT /user/_doc/1001
{
"id": 1001,
"name": "张三",
"age": 10, #年龄由20改为10
"sex": "男"
}
#响应
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1001",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
可以看到数据成功被修改了,在修改一次
PUT /user/_doc/1001
{
"id": 1001,
"name": "张三",
"age": 12 #年龄改为12,同时不传递sex的值
}
#响应
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1001",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}

sex字段丢失了。为了保证数据不丢失,必须每次都附带全部的字段值,全量的覆盖,这不是我们想要的效果。
2.5.4.4.2 局部更新
要进行局部的更新需要在路径上增加额外的参数 _update,传参也有所不同
POST /索引/类型/id/_update
POST /user/_doc/1001/_update
{
"doc":{
"sex":"男"
}
}
#响应
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
# 提示我们应该使用 /{index}/_update/{id}的写法。当然请求还是成功的。
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1001",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}

2.5.4.5 查询用户
GET /user/_doc/1001
#响应
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1001",
"_version" : 4,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 1001,
"name" : "张三",
"age" : 12,
"sex" : "男"
}
}
2.5.5 批量操作
2.5.5.1 批量查询
POST /kase/user/_mget
#请求参数
{
"ids":["1","2","3"]
}
响应
{
"docs": [
{
"_index": "kase",
"_type": "user",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"name": "李四",
"age": 30,
"six": "女",
"height": "165"
}
},
{
"_index": "kase",
"_type": "user",
"_id": "2",
"_version": 1,
"found": true,
"_source": {
"name": "张三",
"age": 21,
"six": "男",
"height": "175"
}
},
{
"_index": "kase",
"_type": "user",
"_id": "3",
"_version": 5,
"found": true,
"_source": {
"name": "王五",
"age": 30,
"six": "男",
"height": 10
}
}
]
}
如果请求的id中有不存在的,并不会影响其他的响应
#请求参数
{
"ids":["1","2","3","300"]
}
#响应
{
"docs": [
{
"_index": "kase",
"_type": "user",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"name": "李四",
"age": 30,
"six": "女",
"height": "165"
}
},
{
"_index": "kase",
"_type": "user",
"_id": "2",
"_version": 1,
"found": true,
"_source": {
"name": "张三",
"age": 21,
"six": "男",
"height": "175"
}
},
{
"_index": "kase",
"_type": "user",
"_id": "3",
"_version": 5,
"found": true,
"_source": {
"name": "王五",
"age": 30,
"six": "男",
"height": 10
}
},
{
"_index": "kase",
"_type": "user",
"_id": "300",
"found": false
}
]
}
2.5.5.2 _bulk操作
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。 请求格式如下:(请求格式不符合json格式要求)
{ action: { metadata }}\n #命令行
{ request body }\n #参数行
{ action: { metadata }}\n
{ request body }\n
批量插入,注意每行末尾的换行符。
命令 GET /_bulk 如果命令行已经指定了索引和类型,则路径中可以不附带。如果路径中附带了则命令行中也可以不指定。
{"create":{"_index":"kase","_type":"user","_id":"6"}}
{"name":"唐僧","age":"23","six":"男","height":"174"}
{"create":{"_index":"kase","_type":"user","_id":"7"}}
{"name":"孙悟空","age":"1024","six":"男","height":"164"}
{"create":{"_index":"kase","_type":"user","_id":"8"}}
{"name":"猪八戒","age":"34","six":"男","height":"176"}
{"create":{"_index":"kase","_type":"user","_id":"9"}}
{"name":"沙悟净","age":"36","six":"男","height":"182"}
#响应
{
"took": 46,
"errors": false,
"items": [
{
"create": {
"_index": "kase",
"_type": "user",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1,
"status": 201
}
},
{
"create": {
"_index": "kase",
"_type": "user",
"_id": "7",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1,
"status": 201
}
},
{
"create": {
"_index": "kase",
"_type": "user",
"_id": "8",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1,
"status": 201
}
},
{
"create": {
"_index": "kase",
"_type": "user",
"_id": "9",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1,
"status": 201
}
}
]
}
批量删除 命令行为 delete,命令如下,此处不做测试。
{"delete":{"_index":"kase","_type":"user","_id":"1"}}
{"delete":{"_index":"kase","_type":"user","_id":"2"}}
{"delete":{"_index":"kase","_type":"user","_id":"3"}}
其他操作类似。
一次请求多少性能高?
- 整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一 个最佳的bulk请求大小。超过这个大小,性能不再提升而且可能降低。
- 最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。
- 幸运的是,这个最佳点(sweetspot)还是容易找到的:试着批量索引标准的文档,随着大小的增长,当性能开始降低,说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以 使用较小的批次。
- 通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的批次好保持在5-15MB大小间。
2.6 文档document入门
2.6.1 默认字段解析
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1001",
"_version" : 4,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 1001,
"name" : "张三",
"age" : 12,
"sex" : "男"
}
}
2.6.1.1 _index
- 含义:此文档属于哪个索引
- 原则:类似数据放在一个索引中。数据库中表的定义规则。如图书信息放在book索引中,用户信息放在user索引中。各个索引存储和搜索时互不影响。
- 定义规则:英文小写。尽量不要使用特殊字符。
2.6.1.2 _type
- 含义:类别。book java node
- 注意:以后的es9将彻底删除此字段,所以当前版本在不断弱化type。不需要关注。见到_type都为 _doc。
2.6.1.3 _id
- 含义:文档的唯一标识。就像表的id主键。结合索引可以标识和定义一个文档。
- 生成:手动(put /index/_doc/id)、自动(put /index/ _doc)
2.6.1.4 _source
含义:插入数据时的所有字段和值。在get获取数据时,在_source字段中原样返回。
2.6.1.5 _version
含义:版本,用来控制并发问题。
对数据的任何变更操作,都会引起版本号的变化,通过版本号的对比来完成并发控制,防止低版本覆盖高版本,即乐观锁。
2.6.2 脚本更新
es可以内置脚本执行复杂操作。例如painless脚本。
注意:groovy脚本在es6以后就不支持了。原因是耗内存,不安全远程注入漏洞。
需求1:修改文档6的num字段,+1。
插入数据
PUT /test_index/_doc/6
{
"num": 0,
"tags": []
}
执行脚本操作
POST /test_index/_doc/6/_update
{
"script" : "ctx._source.num+=1"
}
查询数据
GET /test_index/_doc/6
返回
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "6",
"_version" : 2,
"_seq_no" : 23,
"_primary_term" : 1,
"found" : true,
"_source" : {
"num" : 1,
"tags" : [ ]
}
}
脚本不常用略
2.7 java实现elasticsearch的基本操作
elasticSearch有针对多种语言的客户端,对于java有2中客户端,一种是低级的,一种是高级的。低级客户端更偏向于底层,通过restapi拼接参数完成,一个低级客户端可以通用elasticSearch的各个版本。而高级客户端是对低级客户端的再封装,它更适用于对应的elasticSearch。
这里 我们使用高级客户端,基于springboot。
创建springboot项目,导入elasticSearch的高级客户端依赖。
<properties> <!-- springboot版本为2.1.1,它默认的elasticSearch版本较低,这里我们手动指定版本--> <elasticsearch.version>7.3.2</elasticsearch.version> </properties> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> </dependency>代码编写。
创建连接
RestClientBuilder http = RestClient.builder(new HttpHost("193.112.56.48", 9200, "http")); RestHighLevelClient client = new RestHighLevelClient(http);构建请求
GetRequest getRequest = new GetRequest("user","1001");执行
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);获取结果
if(getResponse.isExists()){ Map<String, Object> source = getResponse.getSource(); System.out.println(source); } //关闭连接 client.close();
2.7.1 文档查询
在基本操作的基础上,我们将client的创建封装一下。
文档信息
- 本文作者:chayedankase
- 本文链接:https://chayedankase.github.io/2020/05/03/Elastic-Stack/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)